
Apache Cassandra data model is significantly much different from other relational databases that we see. This Cassandra tutorial provides you complete and comprehensive details about Cassandra data modeling.
To Download Cassandra.Click Here
Although the CQL (Cassandra query language) is much similar to ordinary query language. But data modeling in Cassandra is totally different. In apace Cassandra bad data modeling can result in decrease in performance of read and write operations. It is usually happens when the developers try implement RDBMS concepts in Cassandra. It is very necessary to keep in mind the rules for big data in common and for Cassandra in particular, As Cassandra works totally in a different manner. In this Cassandra data modeling tutorial you will learn following topics.
Best Practice’s for Cassandra data modeling.
Cassandra Data Model Rules
How to Model you data in Cassandra according to your requirements?
How to handle many to many relationships in Cassandra?
How to handle one to one relationships in Cassandra?
How to handle one to many relationships in Cassandra?
Cassandra Data Model Rules
In Apache Cassandra, write operation is not expensive. We have to keep in mind multiple things while storing data in Cassandra. First and most important is your retrieval mechanism. That how you want to retrieve and what you want to retrieve. As Cassandra does not support multiple RDBMS clauses Like group by, Joins,aggregation, OR clause etc. Once again “store your data in way that it is completely retrievable.” So these points kept in mind while data modeling in Cassandra.
1. Maximize the number of writes
In Cassandra, as already stated write operations are not expensive. Cassandra can be optimized in two ways. The first one is optimization for write heavy and 2nd one is optimization for read heavy. But Cassandra itself supports write heavy. Give better performance with write heavy environment.
2. Data Duplication maximization in Cassandra
Data is denormalized and duplicated for better Cassandra performance. Here there is a trade-off of disk space. But as we know disk space is not an issue now a days vs. the better performance. As cassandra is distributed data base so duplication also help in case any Node (Machine) goes offline. Data request are fulfilled from other locations where the data is duplicated. So Cassandra provides no single point of failure.
Best Practice’s for Cassandra data modeling.
These are best practices used since many years for cassandra data modeling.
Keep less number of partitions read for Read operations
In apache Cassandra partition refer to the group of record who possess the same partition key. When a read operation is initiated the query collects data from different partitions. If query collect the data from more partitions then it takes more time. And this is not an optimized approach.
It does not mean not to create partitions while writing data. Cassandra is also unable to handle large amount of data without partitioning it. So the best practice is to choose a balanced number of partitions.
Distribute data evenly on all Nodes in cassandra Cluster
You have to distribute your data evenly on whole cluster while write operations. Cassandra distributes data on different nodes based on their partition keys. Partition key is the first part of Primary key in Cassandra. So for best performance, chose an integer Primary key. So, that your data evenly distribute on all nodes in Cassandra cluster.
Formulate queries you want to Run while Retrieving Data
First and most Important, Formulate your Data Retrieval Quires
For example, do you need Below Mentioned Operations in your retrieval query?
- Joins
- Group by
- Filtering on which column (Where) etc.
Design tables according to your Data Retrieval Queries
Design your tables according to your Data Retrieval queries.Create only that tables that will surely satisfy your queries. And also try to create table that your search query has to read minimum number of partitions.This is an optimization technique for Cassandra Read Operations in such a way that a minimum number of partitions need to be read.
Selection of Primary Key
Here is the step by guideline how to select a good primary key given along with query.
For Example if you want to create a table of student in Cassandra. Here is your query
Create table Student
(
StudentId int,
StudentName text,
EnrollYear int,
Grade text,
Primary key(StudentId, StudentName)
);
In the above example, table Student,
- Studentid is partition key
- StudentName is the data clustering column
- Data will be distributed on the basis of StudentName. In current scenario, one partition is created with the StudentId. Data retrieval will be slow by this data model due to the bad primary key.
Here is One more Example, table Student.
Create table Student
(
StudentId int,
StudentName text,
EnrollYear int,
Grade text,
Primary key((StudentId, EnrollYear), StudentName)
);
In this example, table Student,
- Year and Studentid are the partition key
- StudentName is the data clustering column.
- Data will be distributed on the basis of StudentName. In current scenario, for each year, Cassandra will create a new partition. All students of the same Enroll year will be on the same node. This primary key Plays an important role for data storage and partitioning mechanism.
If you model you model your data buy keeping these guidelines in mind, your read and write operations will be drastically fast.
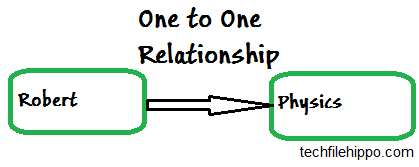
How to Handle One to One Relationship in Cassandra?
In databases, One to one relationship only exists when two database tables has one to one correspondence. For example, if a student is allowed to Enroll in one course at a time. And you want to search a student courses in which he registered in.
So,In current scenario, your table schema or design should have all the details of the student along with the particulars of courses for example, course Name, StudentId of the student, student name, etc.
Create table Courses
(
StudentId int primary key,
StudentName text,
CourseName text,
);
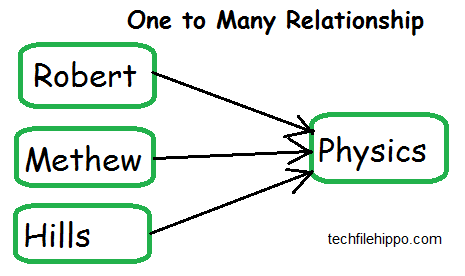
How to handle one to many relationship In cassandra?
If two tables has one to many correspondence. Then there exist a one to many relationships.
For example, a course like physics can be studied by many students, and a student is allowed to register only one course at a time. In this scenario, you want to search all the students that are studying a particular course.
So,it is very easy to search for the records using where clause. Search where the subject name is equal to physics. You will have all student records who are studying a particular course like physics.
Create table Course
(
StudentId int,
StudentName text,
CourseName text,
);
You can retrieve all the student records for a particular course like physics by using this query.
Select * from Course where CourseName='Physics';
How to Handle Many to Many Relationships in Cassandra?
If two tables have many to many correspondences, there exist a many to many relationship.
For example, a student is allowed to register many course, and a course can be studied by many students.
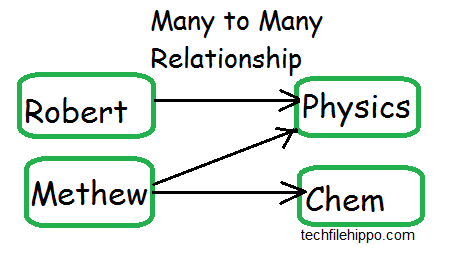
For example, if you want search all the students who are studying physics or chemistry.
And 2nd scenario is if you want to search for a student that how many courses he is studying.
So, in either case, you need two tables i.e. divide the problem into two cases.
In first Case, you have to create a table by which you can run your query to find the courses of a particular student.
Create table StudentCourses
(
StudentId int primary key,
StudentName text,
CourseName text,
);
Now run the below mentioned query to find all the courses of a particular student.
Select * from StudentCourses where StudentId=StdId;
In second case, you have to create a table by which you can run a query to find how many students are studying a particular subject.
Create table CourseStudent
(
CourseName text primary key,
StudentName text,
StudentId int
);
Now run the below mentioned query to find a students in a particular course.
Select * from CourseStudent where CourseName=CourseName;
Difference of Data Modeling In RDBMS and Cassandra
| RDBMS | Cassandra |
| In RDMS, Data is Stored in normalized form | In cassandra, Data is Stored in denormalized form |
| Only stores structured data | Cassandra has Wide row store, Dynamic; structured, semi structured & unstructured data. |
Summary of cassandra Data Model Tutorial.
The crux of the above discussion is that Cassandra data model is totally different from other RDBMS databases. Apache Cassandra data modeling has its own rules.These rules must be followed for good data modeling. Besides these rules, we discussed three different data modeling cases and how to deal with them. If you follow these rules of Cassandra data model, your database will be more fast and robust inits operations.
5 Replies to “Apache Cassandra Data Model”
Comments are closed.